Andrej Karpathy on Software 3.0: Programming LLMs in English and Building for Agents
Andrej Karpathy discusses the profound shifts in software, introducing "Software 3.0" where Large Language Models (LLMs) are programmed in natural language, fundamentally changing how software is developed and interacted with.
- Software has evolved from traditional code [1] to neural network weights [2] and now to natural language prompts [3], making programming accessible to everyone ("vibe coding").
- LLMs behave like utilities, fabs, and especially operating systems, centralizing compute but enabling widespread access, similar to computing in the 1960s.
- LLMs possess emergent human-like "psychology," offering superhuman knowledge but also exhibiting cognitive deficits like hallucinations and amnesia.
- The future of software involves building "partial autonomy" LLM applications that integrate AI for generation and humans for verification, emphasizing fast human-AI collaboration loops and configurable "autonomy sliders."
- To support this shift, digital infrastructure must be redesigned for agents, including LLM-friendly documentation and APIs that allow agents to interact directly.
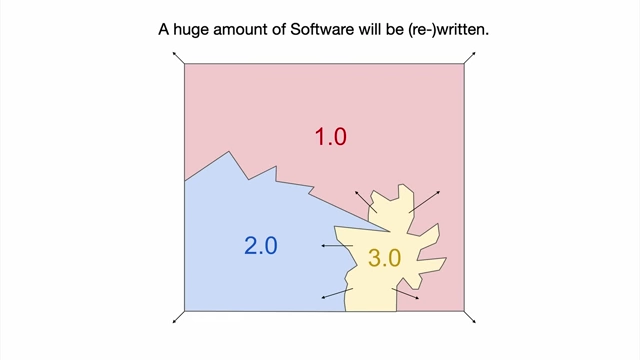
Software evolution from 1.0 to 3.0, showing Software 3.0 eating through the stack [ 00:05:37 ]
Intro [00:00]
Software is undergoing a fundamental change, arguably the most significant in 70 years, with two rapid shifts occurring recently. This transformation presents immense opportunities for those entering the industry, requiring the ability to write and rewrite vast amounts of software.
Software Evolution: From 1.0 to 3.0 [01:25]
The talk outlines a progression in software paradigms:
- Software 1.0 = Code [01:42]
- This refers to traditional computer code written by humans (e.g., C++, Python).
- It programs a "classical computer."
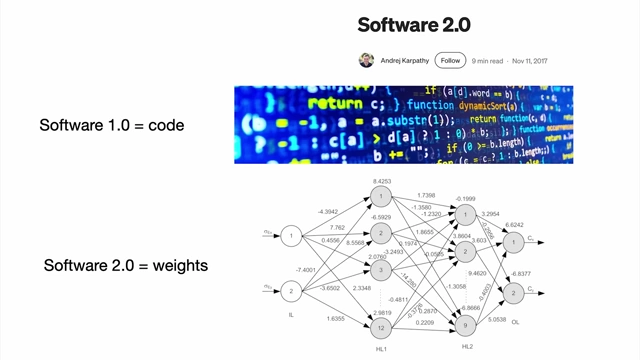
Comparison of Software 1.0 (code) and Software 2.0 (weights) [ 00:01:54 ]
- Software 2.0 = Weights [01:46]
- This refers to neural networks, where the "software" is the learned weights of the network.
- Instead of writing explicit code, developers curate datasets and run optimizers to generate these weights.
- The "Map of GitHub" for Software 1.0 finds its equivalent in "HuggingFace Model Atlas" for Software 2.0.

Comparison of Software 1.0 (code repositories) and Software 2.0 (neural network models) [ 00:02:20 ]
- Software 3.0 = Prompts [03:09]
- Large Language Models (LLMs) are a new kind of computer that are programmable.
- Programming LLMs is done via natural language prompts, making English a new, unique programming language.
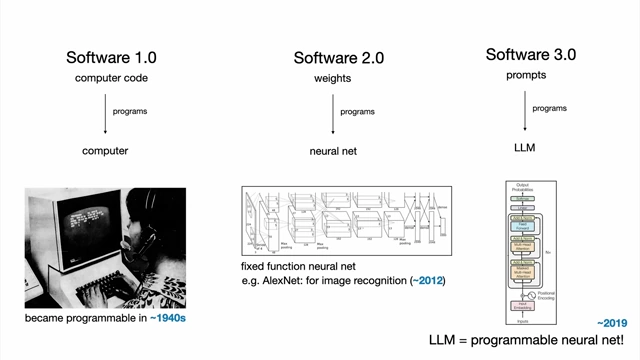
Illustration of Software 1.0, 2.0, and 3.0 as programming paradigms for different types of computers [ 00:03:18 ] - Example: Sentiment classification can be done with Python code [1], a trained neural net [2], or a few-shot prompt to an LLM [3].

Comparison of Software 1.0, 2.0, and 3.0 programming for sentiment classification, showing increasing abstraction [ 00:03:40 ]
- Analogy: Software 2.0 "Eating" 1.0 (Tesla Autopilot) [04:40]
- In Tesla Autopilot, early functionality was implemented in Software 1.0 (C++ code).
- Over time, as neural networks (Software 2.0) grew in capability, much of the C++ code was replaced and functionalities migrated to the neural net stack.
- This demonstrated Software 2.0 literally "eating through" the Software 1.0 stack.

Diagram showing Software 2.0's footprint growing and "eating" into Software 1.0 within a system, like Tesla Autopilot [ 00:04:38 ]
- Current State: [05:37]
- We now have three distinct programming paradigms: 1.0 (code), 2.0 (weights), and 3.0 (prompts).
- Developers entering the industry should be fluent in all three, as each has pros and cons, requiring fluid transitions between them for different functionalities.
Illustration of Software 1.0, 2.0, and 3.0 evolving and interacting, with Software 3.0 "eating" into the existing stack [ 00:05:37 ] - The "Map of GitHub" now includes an emerging area for Software 3.0 (LLM prompts in English).

Map of GitHub (Software 1.0) and HuggingFace Model Atlas (Software 2.0) with an emerging Software 3.0 area [ 00:04:02 ]
LLMs as Utilities, Fabs, and Operating Systems [06:10]
Andrej Karpathy proposes analogies to understand LLMs:
- Properties of Utilities [06:30]
- LLM labs (e.g., OpenAI, Gemini, Anthropic) incur significant Capital Expenditure (CAPEX) to train LLMs (analogous to building an electricity grid).
- Operational Expenditure (OPEX) is used to serve intelligence via homogeneous APIs (prompt, image, tools, etc.).
- Access is metered (e.g., per million tokens), similar to paying for electricity.
- Users demand low latency, high uptime, and consistent quality, much like demanding consistent voltage from a grid.
- Tools like OpenRouter act as "transfer switches," allowing users to switch between different LLM providers (analogous to switching between grid, solar, or generator).
- "Intelligence brownouts" occur when state-of-the-art LLMs go down, meaning the "planet gets dumber" due to increasing reliance.
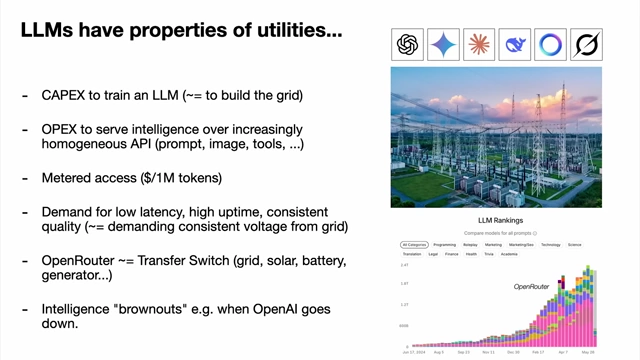
LLMs have properties of utilities, showing capex, opex, metered access, and reliability demands, alongside a power grid and LLM rankings [ 00:06:49 ]
- Properties of Fabs [08:00]
- Building LLMs involves huge CAPEX, akin to building semiconductor fabrication plants.
- There's deep tech tree R&D and valuable secrets centralized within LLM labs.
- However, LLMs are software, making them more malleable and less defensible than physical fabs.
- Analogy: Training on NVIDIA GPUs is like a "fabless" model, while training on Google's TPUs is like owning the "fab" (Intel model).

LLMs have properties of fabs, illustrating capital expenditure, tech tree R&D, and examples of large GPU clusters [ 00:08:09 ]
- Properties of Operating Systems [09:09]
- LLMs are increasingly complex software ecosystems, not simple commodities.
- The ecosystem resembles traditional OS: a few closed-source providers (like Windows, macOS) and an open-source alternative (like Linux, with Llama ecosystem as an early approximation).

LLMs have properties of operating systems, showing analogies to Windows, macOS, and Linux distributions and LLM providers [ 00:09:18 ] - An "LLM OS" vision shows the LLM as a central CPU, interacting with peripheral devices, classical computers (for tools), file systems, browsers, and other LLMs.
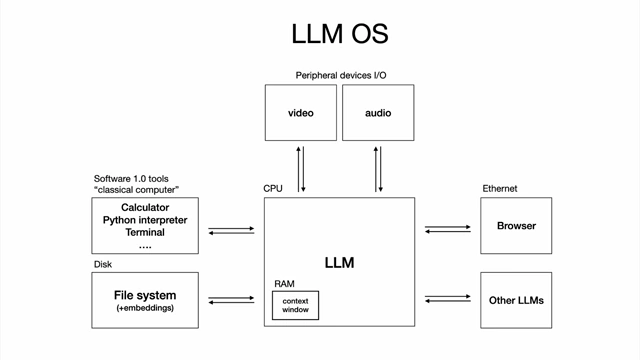
Diagram of an LLM OS showing the LLM as a central processing unit interacting with various components like I/O, tools, file systems, and other LLMs [ 00:10:18 ] - Just as apps like VS Code run on Windows, Linux, or Mac, LLM apps like Cursor can run on different LLMs (GPT, Claude, Gemini).
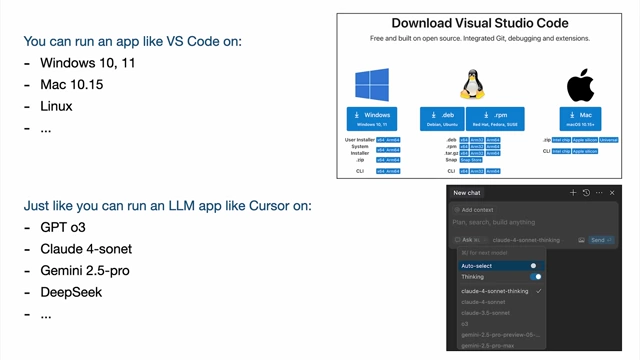
Comparison of running VS Code on various operating systems and an LLM application like Cursor on various LLMs [ 00:10:48 ] - Historical Computing Analogies (1960s) [11:04]
- LLM compute is currently very expensive, forcing centralization in the cloud.
- Users are "thin clients" interacting over the network, with compute often batched (time-sharing era of mainframe computing).


LLM Psychology: People Spirits and Cognitive Quirks [14:39]
To effectively program LLMs, one must understand their "psychology."
- LLMs as "People Spirits" [14:48]
- LLMs are stochastic simulations of people, with the simulator being an autoregressive Transformer.
- Trained on human data, they exhibit an emergent, human-like psychology.

Conceptual image of an LLM as a "people spirit" with an autoregressive Transformer diagram, suggesting emergent psychology [ 00:14:57 ]
- Superhuman Abilities [15:28]
- They possess encyclopedic knowledge and memory, far exceeding any single human (likened to the character Rainman).

Images illustrating encyclopedic knowledge and memory, comparing it to a savant from the movie Rainman [ 00:15:37 ]
- They possess encyclopedic knowledge and memory, far exceeding any single human (likened to the character Rainman).
- Cognitive Deficits [16:06]
- Hallucinations: LLMs frequently make up information and lack sufficient internal self-knowledge.

Image symbolizing hallucinations as a glowing cat visible only to one person in a library [ 00:16:16 ] - Jagged Intelligence: They can be superhuman in some problem-solving domains but make elementary mistakes in others.

Image depicting a person struggling with simple math (2+2=5), symbolizing jagged intelligence in LLMs [ 00:16:22 ] - Anterograde Amnesia: LLMs do not learn continually or consolidate knowledge over time like humans "sleeping." Context windows are merely working memory that gets wiped, requiring explicit programming for knowledge retention (likened to movies like Memento or 50 First Dates).

Image of a student struggling to remember, symbolizing anterograde amnesia in LLMs where context windows act as temporary working memory [ 00:16:47 ] - Gullibility: LLMs are susceptible to prompt injection risks and might leak private data due to their trusting nature.

Image of a person holding books, with "TRUST ME" on the spine, symbolizing gullibility and prompt injection risks in LLMs [ 00:17:46 ]
- Hallucinations: LLMs frequently make up information and lack sufficient internal self-knowledge.
- Summary of LLM Psychology: [17:55]
- LLMs are a "lossy simulation of a savant with cognitive issues."
- The challenge is to program them effectively by working around their deficits while leveraging their superhuman capabilities.

Collage summarizing LLM psychology, including hallucinations, memory, jagged intelligence, and gullibility [ 00:17:56 ]
Designing LLM Apps with Partial Autonomy [18:22]
There are significant opportunities in building LLM-powered applications.
- Partial Autonomy Apps: [18:26]
- Instead of directly interacting with LLMs like a terminal (e.g., copy-pasting code to ChatGPT), it's more effective to use dedicated LLM applications.

Image of a ChatGPT interface discussing code next to an old computer terminal, suggesting direct chat is like a terminal interaction [ 00:18:36 ]
- Instead of directly interacting with LLMs like a terminal (e.g., copy-pasting code to ChatGPT), it's more effective to use dedicated LLM applications.
- Example: Anatomy of Cursor (coding assistant) [18:47]
- Traditional Interface + LLM Integration: Cursor combines a standard code editor with an LLM chat sidebar.
- Context Management: LLMs handle packaging relevant state into a context window before calls.
- Orchestration of Multiple LLM Models: Cursor orchestrates various models (embedding, chat, diff application) seamlessly.
- Application-Specific GUI: A graphical user interface is crucial for auditing LLM work visually (e.g., seeing red/green diffs) and taking quick actions (e.g.,
Cmd+Yto accept), speeding up the human-AI loop.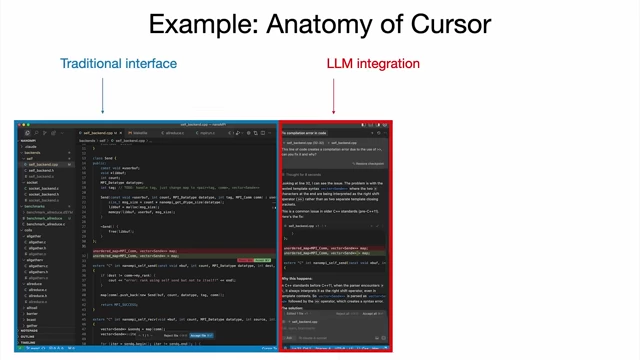
Anatomy of Cursor, highlighting the traditional interface and LLM integration for coding assistance [ 00:19:06 ] - Autonomy Slider: Cursor offers varying levels of LLM autonomy, from simple tap completion to modifying entire files or repositories, allowing users to tune control based on task complexity.

Diagram showing the autonomy slider in Cursor, ranging from tap completion to full agent mode that modifies entire repositories [ 00:20:22 ]
- Example: Anatomy of Perplexity (search engine) [21:03]
- Perplexity also embodies these principles: it packages information, orchestrates multiple LLMs, provides a GUI to audit sources, and features an autonomy slider for different search depths (quick search, research, deep research).

Anatomy of Perplexity, highlighting context packaging, multiple LLM models, application-specific GUI, and an autonomy slider for search depth [ 00:21:06 ]
- Perplexity also embodies these principles: it packages information, orchestrates multiple LLMs, provides a GUI to audit sources, and features an autonomy slider for different search depths (quick search, research, deep research).
- Designing Software for Partial Autonomy [21:30]
- Software like Photoshop or Unreal Engine needs to consider how LLMs can "see" and "act" in the same ways a human can, and how humans can effectively supervise and stay in the loop with AI actions.
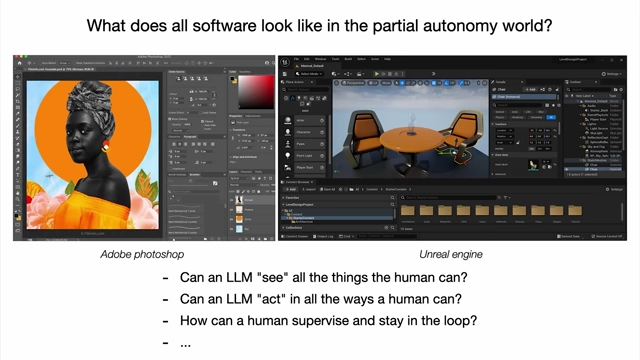
Interfaces of Adobe Photoshop and Unreal Engine, posing questions about how LLMs can perceive and act within such complex software environments [ 00:21:34 ]
- Software like Photoshop or Unreal Engine needs to consider how LLMs can "see" and "act" in the same ways a human can, and how humans can effectively supervise and stay in the loop with AI actions.
- Human-AI Collaboration Loops [23:40]
- In LLM apps, AI typically handles generation, while humans handle verification.
- The goal is to speed up this generation-verification loop for higher productivity.
- 1. Speed up Verification: This is achieved through effective GUIs and visual representations that leverage human computer vision, making it easier and faster to audit AI output compared to reading raw text.
- 2. Keep AI on the Leash: Avoid giving LLMs too much autonomy prematurely. Large, unverified diffs are counterproductive. It's better to work in small, incremental chunks and provide concrete prompts to ensure successful verification and prevent the AI from "getting lost in the woods."
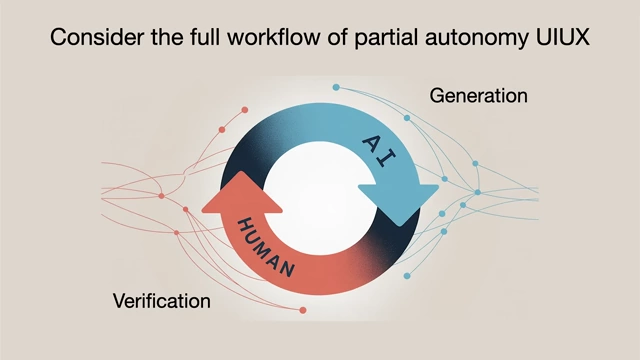
Diagram showing the human-AI collaboration loop, with AI for generation and human for verification, emphasizing a fast cycle [ 00:22:05 ] - AI Education Example: Rather than asking an LLM to "teach me physics" broadly, separate apps can be built: one for a teacher to create auditable courses with AI, and another for serving these courses to students, keeping the AI focused within a defined syllabus.

Diagram illustrating AI assistance in education, with one app for teachers creating auditable courses and another for students consuming them [ 00:25:35 ]
- Lessons from Tesla Autopilot & Autonomy Sliders [26:00]
- Andrej's experience with Tesla Autopilot, a partial autonomy product, highlights the importance of GUIs (instrument panel showing what the neural network "sees") and autonomy sliders (gradually increasing autonomous tasks over time).

Tesla Autopilot as an example of a partial autonomy product with a GUI and an adjustable autonomy slider for various driving tasks [ 00:25:51 ] - The journey to full self-driving (driving agents) has been long (over a decade since 2013 demos), still involving human intervention (teleoperation).

An image of a Waymo self-driving car from 2013, illustrating the long and complex journey towards full autonomous driving [ 00:26:24 ] - This suggests caution against premature declarations of AGI or "the year of agents," emphasizing that humans will remain in the loop for complex software for some time.
- Andrej's experience with Tesla Autopilot, a partial autonomy product, highlights the importance of GUIs (instrument panel showing what the neural network "sees") and autonomy sliders (gradually increasing autonomous tasks over time).
- The Iron Man Analogy: Augmentation vs. Agents [27:52]
- The Iron Man suit exemplifies both augmentation (Tony Stark directly piloting) and agents (the suit acting autonomously).

The Iron Man Suit analogy, distinguishing between augmentation (Tony Stark in control) and agent (suit acting autonomously) modes [ 00:28:14 ] - Currently, the focus should be on building "Iron Man suits" (augmentations, partial autonomy products with custom GUIs and autonomy sliders), not "Iron Man robots" (flashy, fully autonomous agents that are still fallible).
- Products should integrate an "autonomy slider" to enable a gradual shift from augmentation towards higher levels of agentic behavior over time.

A table showing preferable development focuses: Iron Man suits over robots, partial autonomy products over flashy demos, and including custom GUIs, fast loops, and autonomy sliders [ 00:28:28 ]
- The Iron Man suit exemplifies both augmentation (Tony Stark directly piloting) and agents (the suit acting autonomously).
Vibe Coding: Everyone is Now a Programmer [29:06]
The ability to program LLMs in English has made software highly accessible, leading to a new phenomenon called "vibe coding."
- Natural Language Interface: English as a programming language means anyone who speaks English can now "program" computers. This is unprecedented, as traditional programming required years of study.
- "Vibe Coding" Concept: A term coined by Andrej Karpathy to describe a mode of software development where one "gives in to the vibes" and lets LLMs (like Cursor Composer) generate code, focusing on broad descriptions rather than intricate details, and accepting changes without deep auditing.
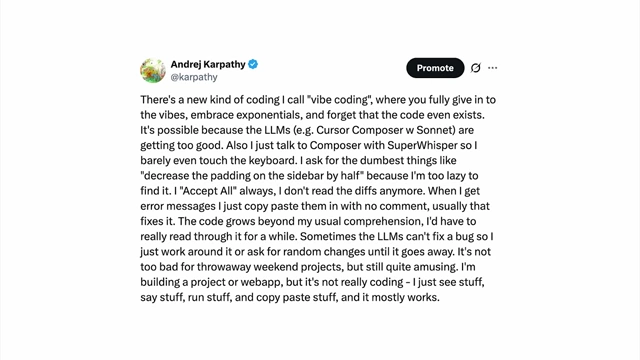
Andrej Karpathy's tweet introducing "vibe coding" as a new, intuitive approach to programming with LLMs [ 00:29:44 ] - Real-World Examples of Vibe Coding:
- Kids vibe coding, creating simple applications, suggesting it could be a "gateway drug" to software development for a new generation.

Children engaged in "vibe coding" at computers, symbolizing AI's potential to unleash a new generation of creative builders [ 00:30:53 ] - Andrej built a basic iOS app in a day without knowing Swift, highlighting how LLMs abstract away language-specific complexities.

Screenshot of a simple iOS application, described as being built in a day using "vibe coding" without knowing Swift [ 00:31:08 ] - Developed "MenuGen" (menugen.app), an app that takes a picture of a restaurant menu and generates images for each item.

Image showing a physical restaurant menu transformed into a digital menu with images by MenuGen, an app built using "vibe coding" [ 00:31:43 ] - A live demonstration of MenuGen shows users taking a picture of a menu and receiving a digital version with images for each item.
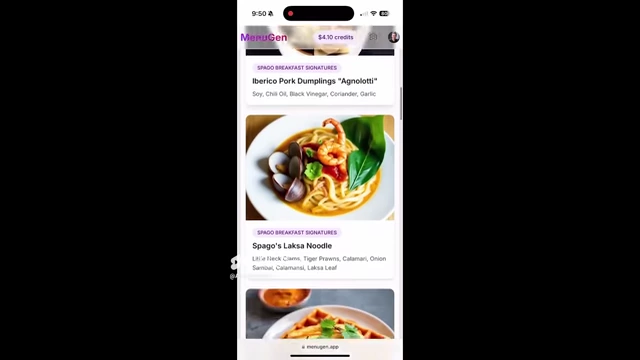
A mobile screen recording of the MenuGen app, demonstrating how it digitizes a physical menu and adds corresponding food images [ 00:32:07 ]
- Kids vibe coding, creating simple applications, suggesting it could be a "gateway drug" to software development for a new generation.
- Challenge: Devops is the New Bottleneck: [32:21]
- While vibe coding makes generating code easy (the "easy part"), making the application "real" (e.g., adding authentication, payments, deployment, domain names) is still hard.
- These tasks primarily involve manual "clicking things" in browser-based devops interfaces designed for humans, which is slow and frustrating for LLMs/automation.

A list highlighting that while coding (e.g., with LLM APIs) was the easiest part, tasks like deployments, domain names, authentication, and payments were the hardest, involving manual "clicking things" in browsers [ 00:32:23 ]
Building for Agents: Future-Ready Digital Infrastructure [33:39]
The rise of human-like AI agents necessitates a fundamental shift in how digital infrastructure is designed.
- New Category of Digital Consumer/Manipulator: Besides humans (via GUIs) and traditional computers (via APIs), there's now a new category: agents, which are computers but human-like in their interaction patterns. They need to interact with software infrastructure.

Slide showing three categories of digital information consumers/manipulators: Humans (GUIs), Computers (APIs), and NEW Agents (computers, but human-like) [ 00:34:10 ] - Building for Agents Requires New Approaches:
lm.txtfor LLMs: Analogous torobots.txtfor web crawlers, anlm.txtfile (simple markdown) could directly inform LLMs about a domain's purpose, making it easier for them to understand and interact than parsing complex HTML.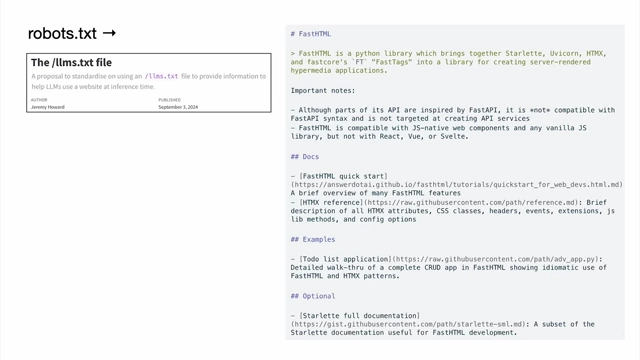
Comparison of robots.txt for web crawlers and a proposed lm.txt file (simple markdown) for directly informing LLMs about a website's purpose [ 00:34:13 ] - Docs for LLMs: Documentation traditionally written for humans (with lists, bold text, images) needs to be adapted for LLMs, ideally in markdown format for easy understanding.

Example of Vercel documentation formatted for people, showing lists, bold text, and images, which are not directly accessible to LLMs [ 00:34:40 ] - Actions for LLMs: Instructions like "click this button" in documentation are problematic for LLMs. Instead, docs should provide machine-executable actions, such as
curlcommands, allowing agents to perform tasks directly.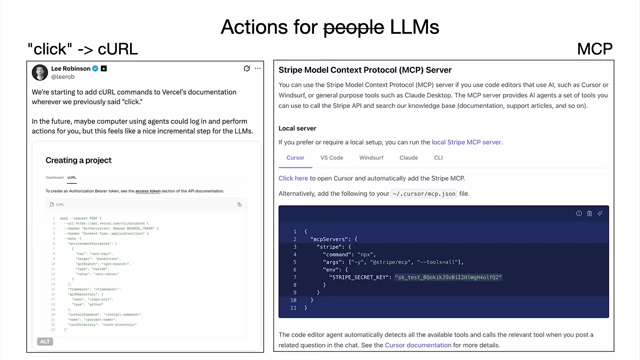
Comparison of documentation for people versus LLMs, showing how "click" instructions can be replaced with machine-executable curl commands and discussing Model Context Protocol [ 00:35:52 ] - Context Builders (e.g., Gitingest, Devin DeepWiki): Tools that help ingest and summarize information (like GitHub repositories) into LLM-friendly formats (e.g., concatenated text, directory structures, analytical summaries), making it easier for LLMs to consume and reason about complex data.
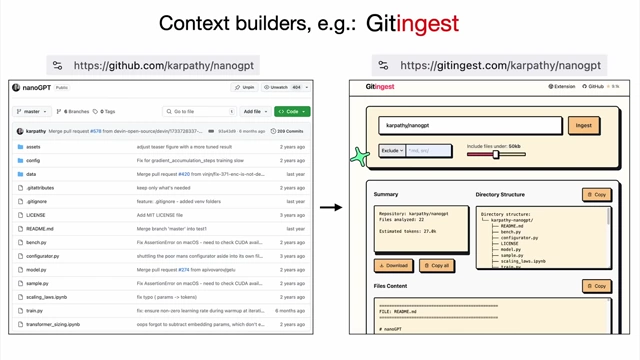
Example of Gitingest, a tool that transforms a GitHub repository into an LLM-friendly format, including a summary and directory structure [ 00:36:42 ] 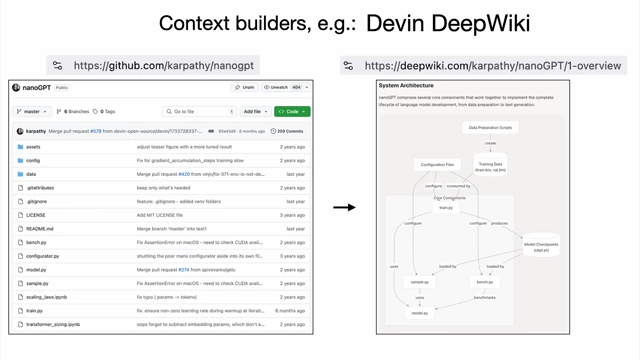
Example of Devin DeepWiki, which generates analytical documentation from a GitHub repository for LLMs, showing a system architecture diagram [ 00:37:02 ]
- Meeting LLMs Halfway: While LLMs are developing capabilities to interact with traditional GUIs (e.g., "clicking stuff"), it is still more efficient and less expensive to adapt our digital infrastructure to meet them halfway by providing machine-readable formats and executable instructions. This is particularly relevant for the "long tail" of software that may not be actively updated for full agent compatibility.

A screenshot from "Introducing Operator", an agent that uses a browser to perform tasks, demonstrating an LLM interacting with a traditional GUI [ 00:37:46 ]
Summary: We’re in the 1960s of LLMs — Time to Build [38:14]
- Software is fundamentally changing again, moving through Software 1.0 (code), 2.0 (weights), and now 3.0 (prompts in English).
- LLMs combine properties of utilities, fabs, and especially operating systems, echoing the early 1960s era of computing where systems were centralized and accessed via time-sharing.
- A key new aspect is the unprecedented, sudden access billions of people have to these powerful models, making it a critical time to program them.
- LLMs, while superhuman in some ways, also possess human-like cognitive deficits (hallucinations, amnesia, gullibility) that require careful consideration in design.
- The industry should focus on building "partial autonomy" LLM applications with custom GUIs and "autonomy sliders" that enable a fast generation-verification loop between AI and humans.
- Digital infrastructure must evolve to "build for agents," providing LLM-legible documentation and actions.
- The next decade will see a significant shift along the "Iron Man suit" autonomy slider, from augmentation to more capable agents. It's an exciting time to build in this evolving landscape.
Comprehensive summary slide combining key visuals and concepts from the presentation: software evolution, LLM analogies, psychology, app design, and building for agents [ 00:38:12 ]